1. 단일 서버

웹 앱, 데이터베이스, 캐시 등이 전부 서버 한 대에서 실행된다.
1. 사용자는 도메인을 이용해서 웹사이트에 접속
2. 이 접속을 위해서는 도메인 이름을 DNS에 질의하여 IP 주소로 변환하는 과정이 필요
2. DNS 조회 결과로 IP 주소가 반환 (웹 서버의 주소)
3. 해당 IP 주소로 HTTP 요청이 웹 서버에 전달
4. 요청을 받은 웹 서버는 HTML 페이지나 JSON 형태의 응답을 반환

2. 데이터베이스
사용자가 증가할 경우, 하나의 서버로는 부족해진다.
여러 서버를 두어야 함.
웹/모바일 트래픽 처리(웹 계층) 서버, 데이터베이스(데이터 계층) 서버 분리
데이터베이스의 종류
- 관계형 데이터베이스 (RDBMS)
- MySQL, Oracle, PostgreSQL
- 테이블, 열, 컬럼
- join 지원 O
- 비-관계형 데이터베이스(NoSQL)
- CouchDB, Neo4j, Cassandra, HBase, Amazon DynamoDB
- NoSQL의 4가지 분류
- 키-값 저장소 / 그래프 저장소 / 칼럼 저장소 / 문서 저장소
- join 지원 X
NoSQL 활용 예시
- 아주 낮은 응답 지연시간(latency) 요구되는 경우
- 다루는 데이터가 비정형(unstructured)이라 관계형 데이터가 아니다.
- 데이터(JSON, YAML, XML 등)를 직렬화하거나(serialize) 역직렬화(deserial-ize)할 수 있기만 하면 됨
- 아주 많은 양의 데이터를 저장해야 하는 경우
3. 수직적 규모 확장 vs 수평적 규모 확장
스케일 업(scale up)
- 수직적 규모 확장 프로세스
- 서버에 고사양 자원(더 좋은 CPU, 더 많은 RAM)을 추가하는 행위
- 단점
- 확장의 한계, 한 대의 서버에 CPU나 메모리를 무한대로 증설 불가능
- 장애에 대한 자동복구(failover)나 다중화(redundancy)방안 없음, 장애 발생 시 서비스 중단
스케일 아웃(scale out)
- 수평적 규모 확장 프로세스
- 더 많은 서버를 추가하여 성능 개선하는 행위
- 스케일 아웃 시 서버간 부하를 분산시키기 위해 로드밸런서 사용

3-1. 로드밸런서
- 부하 분산 집합에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할
- 사용자가 로드밸런서의 공인IP로 접속
- 로드밸런서가 웹 서버로 사설IP 통신
- 로드밸런서는 자동적으로 트래픽을 분산해주기 때문에 서버1이 다운되면, 모든 트래픽은 서버2로 전송
- 트래픽이 증가해도 웹서버 계층에 서버를 추가 (스케일아웃)하면 로드밸런서가 자동으로 트래픽을 분산
3-2. 데이터베이스 다중화
- master - slave 관계를 설정하고 slave 서버에 사본을 저장하는 방식
- master : 쓰기연산 + 읽기 연산
- slave : master의 사본을 받아 읽기 연산만 가능
- 성능 : master-slave 다중화 모델에서 읽기 연산이 slave 서버로 분산된다. 병렬로 처리될 수 있는 질의(query) 수가 늘어나 성능이 향상
- 안정성 : 데이터베이스 서버 가운데 일부가 파괴되도 데이터의 보존이 가능
- 가용성 : 여러 지역에 데이터를 복사해서, 하나의 데이터가 장애가 발생해도 다른 서버에서 복구 가능
master 서버가 다운되면 slave 서버중 하나가 master 서버로 승격되며, 데이터를 최신 상태로 복구하기 위해 복구 스크립트를 돌려 부족한 데이터를 추가해준다.
DB의 종류에 따라 자동으로 slave 서버가 승격되는 경우가 있고, 수동으로 승격시켜주어야 하는 경우가 있다. (MySQL 은 수동)
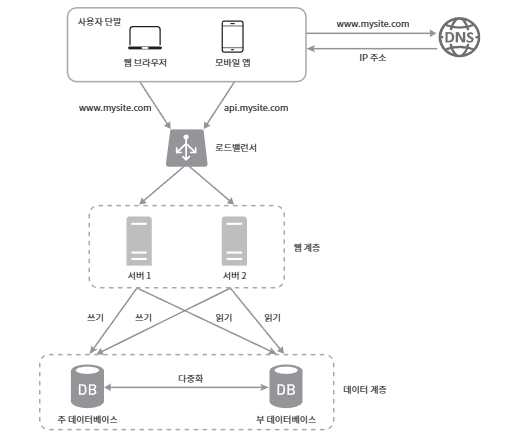
- 사용자는 DNS에서 로드밸런서의 공인IP를 발급
- 사용자는 공인IP로 로드밸런서에 접속
- HTTP 요청을 사설IP를 통해 웹서버로 전달
- 웹서버는 읽기 연산을 slave 서버로 / 쓰기 연산을 master 서버로 전달
4. 캐시 (Cache)
- 애플리케이션의 성능은 데이터베이스를 얼마나 자주 호출하느냐에 따라 크게 달라진다.
- 실행이 오래걸리는 연산이나 자주 참조되는 데이터를 메모리 안에 두고, 요청이 보다 빨리 처리될 수 있도록 하는 저장소
캐시 계층(Cache tier)
- 데이터가 잠시 보관되는 곳. 데이터베이스보다 빠르다.
- 데이터베이스 부하를 줄일 수 있고, 캐시 계층의 규모를 독립적으로 확장 가능
- 읽기 주도형 캐싱 전략 : 웹서버가 캐시에 응답이 있는지 확인 후 반환. 없다면 DB 조회후 캐싱 및 응답

캐시 사용 주의 사항
- 참조가 빈번하게 일어나는 상황에서만 사용하자.
- 캐시는 휘발성 메모리이기 때문에, 중요한 데이터는 저장하지 말자.
- 캐시의 만료정책을 잘 설정하자.
- 캐시를 너무 오래 남기면 : 원본과 차이가 날 수 있음, 메모리를 많이 잡아먹음.
- 캐시를 짧게 남기면 : 캐싱을 더 자주해야 함. DB 조회가 더 빈번해짐
- 일관성(consistency) : 캐싱된 데이터가 원본과 동일한가?
- DB의 데이터가 갱신될 때, 캐싱된 데이터도 갱신되어야 한다. (??)
- 읽기 성능이 중요하고, 데이터의 실시간 일관성이 크게 중요하지 않은 서비스일 경우, 꼭 일관성을 즉시 맞출 필요는 없다고 생각함. (필자 생각)
- 캐시 서버를 하나만 둘 경우, 단일 장애 지점(Single Point of Failure, SPOF)이 되어버릴 수 있다. 전체 시스템이 동작 중지가 될 수 있기 때문에 여러 지역에 걸쳐 캐시 서버를 분산해야 한다.
- 캐시 메모리를 너무 작게 잡을 경우, 데이터가 캐시에 자주 밀려나는 문제가 생긴다. 이 경우 캐시 메모리를 과할당(overprovision)한다.
- 데이터 방출 정책을 적절하게 적용
- LRU(Least Recently Used) : 사용 시점이 가장 오래된 데이터부터 삭제
- LFU(Least Frequently Used) : 사용 빈도가 가장 낮은 데이터부터 삭제
- FIFO(First In First Out) : 가장 먼저 들어온 데이터를 가장 먼저 삭제
- 이미 대부분의 캐싱 솔루션 (Redis 등) 에는 데이터 방출 정책을 지원하고 있어서, 어플리케이션에서 따로 설정할 필요는 없는듯?
5. CDN (콘텐츠 전송 네트워크)
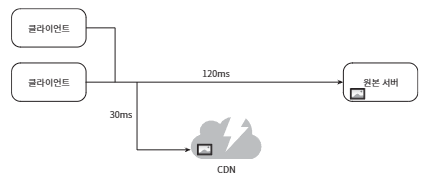
- 정적 콘텐츠를 전송하는 데 쓰이는 지리적으로 분산된 서버의 네트워크
- image, video, css, js 등의 파일을 캐싱한다.
- 동적 콘텐츠 캐싱 : 요청 정보에 기반하여 HTML 페이지를 캐싱하는 것. (요청 정보 : request path/header/cookie/query ... )
CDN 동작 과정
- 사용자가 웹사이트 방문시, 사용자에게 가까운 CDN 서버가 정적 콘텐츠를 전달한다.
- 정적 콘텐츠 : js, css, 이미지 등등

CDN 사용 주의 사항
- 비용 : 써드파티로 운영되어 CDN으로 들어가고 나가는 데이터량에 따라 과금됨. 자주 사용되는 컨텐츠만 캐싱하자!
- TTL : 너무 길면 컨텐츠의 신선도가 떨어짐 / 너무 짧으면 원본서버에 너무 자주 접속함 (캐싱과 동일)
- 장애 : CDN 자체가 다운됐을 때 원본 서버로부터 직접 컨텐츠를 가져오도록 구성해놓아야 한다.

6. 무상태 웹 계층
- 웹 서버에 데이터를 보관하지 말자.
- 웹 계층을 수평적으로 확장하기 위해서는 상태 정보를 웹 계층에서 제거해야 한다.
- 무상태 웹 계층 : 상태 정보를 RDBMS, NoSQL 같은 지속성 저장소에 보관하고, 필요할 때 가져온다.
상태 정보 의존적인 아키텍처

- 상태 정보 보관 서버 : 클라이언트 정보(상태 유지)로 요청들 사이에 공유
- 사용자 A의 정보는 서버 1에 저장되어 있고, 사용자 A를 인증하려면 HTTP 요청이 서버 1으로 전송해야 한다.
- 같은 클라이언트의 요청은 같은 서버로 전송되어야 하는 문제점 때문에 로드밸런서의 고정 세션 (sticky session) 기능을 사용하지만, 부담을 줄 수 있고 확장성에 좋지 않다.

무상태 아키텍처
- 사용자로부터 HTTP 요청은 어떤 웹 서버로도 전달될 수 있기 때문에 상태 정보가 필요한 경우 공유 저장소(shared storage)로부터 데이터를 가져온다.
- 단순한 구조, 안정적, 규모 확장 용이

7. 데이터 센터
- 여러 지역의 사용자가 쾌적하게 사용할 수 있도록 지원해야 할 때 사용한다.
- 지리적 라우팅 : 사용자에게 가장 가까운 데이터 센터로 안내되는 것
- geoDNS는 사용자의 위치에 따라 도메인 이름을 어떤 IP 주소로 변환할지 결정해주는 DNS 서비스

8. Message Queue (메시지 큐)

- MQ : 메시지의 무손실을 보장하는 비동기 통신 컴포넌트
- 무손실 (durability) : MQ에 보관된 메시지는 소비자가 꺼내기 전까지는 안전하게 보관된다.
- 생산자 : producer / publisher
- 소비자 : consumer / subscriber
장점
- 서비스간 결합이 느슨해져, 규모를 확장하기 좋다.
- 이미 MQ 에 있는 메시지는 생산자 서버가 다운되어도 소비자가 소비할 수 있으며, 소비자 서버가 다운되어도 생산자는 메시지를 발행할 수 있다.
- 보통 시간이 오래걸리는 작업이나, 서비스에서 분리시켜 작업 프로세스를 줄이고자 할 때 사용.
9. 로그 & 메트릭 & 자동화
- 로그
- 에러 로그 모니터링은 시스템의 오류와 문제들을 쉽게 찾아낼 수 있다.
- 메트릭
- 잘 수집된 메트릭은 사업 현황에 유용한 정보를 얻을 수 있고, 시스템의 상태를 쉽게 파악 가능하다.
- 호스트 단위 메트릭 : CPU, 메모리, 디스크 I/O
- 종합 메트릭 : 데이터베이스 계층의 성능, 캐시 계층의 성능
- 핵심 비즈니스 메트릭 : 일별 능동 사용자, 수익, 재방문
- 자동화
- 시스템이 복잡해질 때, 개발 생산성을 높이기 위해 사용

10. 데이터베이스 규모 확장
- 데이터가 많아지면 데이터베이스도 증설해야 함.

1. 수직적 확장(Scale up)
- 고성능 자원(CPU, RAM, 디스크) 을 증설하는 방법
- ex) stackoverflow 는 2013년 방문자 1,000만명에 대한 데이터를 master DB 한대로 처리함. (쌉고성능)
- SPOF 위험성이 크다.
2. 수평적 확장(sharding)
- 더 많은 서버를 추가해 성능 향상
- sharding : 대규모 데이터베이스를 샤드(shard) 단위로 분할하는 기술
- 샤드는 같은 스키마를 사용하지만, 보관되는 데이터는 중복 X
샤딩 : DB 자체를 물리적으로 분산
파티셔닝 : 하나의 DB 내에서 데이터를 논리적으로 분산
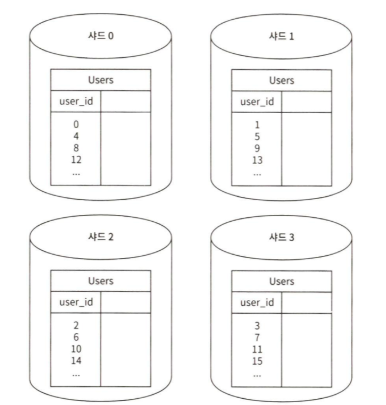
[샤딩 : Sharding]
- DB 자체를 물리적으로 분산하는 방식
- 샤딩 키 선정이 중요함.
- 목적 : DB 수평 확장성을 높이고 대규모 데이터 처리를 분산하여 성능 개선
- 한 샤드가 실패해도 다른 샤드는 영향받지 않는다.
- 문제
- 샤드간 데이터 분포가 균등하지 않을 때 샤드 소진 현상 발생 가능
- 유명인사 문제 : 특정 샤드에 질의가 집중되어 과부화되는 문제 (재할당 or 분산 필요)
- 복잡성 : 샤드 키 설계 및 관리가 어렵고 어플리케이션에셔 샤딩로직이 필요할수도있음
- join 못함 --> 비정규화해서 하나의 테이블에서만 질의가 수행될수있도록 해야 함.
[파티셔닝 : Partitioning]
- 하나의 데이트베이스 내에서 데이터를 논리적으로 분리
- 목적 : 대규모 데이터를 관리하기 쉽고, 쿼리성능을 개선하기 위함.
- 문제 : 결국 데이터베이스는 하나라 확장이 어려움.
요약
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 많은 데이터 캐싱
- 여러 데이터 센터 지원
- 정적 콘텐츠는 CDN으로 서비스
- 데이터 계층은 샤딩을 통해 규모 확장
- 각 계층은 독립적 서비스로 분할
- 시스템 모니터링 & 자동화 도구 활용

'대규모 시스템 설계 기초' 카테고리의 다른 글
| [3장] 시스템 설계 면접 공략법 (0) | 2025.01.25 |
|---|---|
| [2장] 개략적인 규모 추정 (0) | 2025.01.18 |